Fala pessoal, no PET Redação desta semana iremos entender mais sobre uma das áreas mais comentadas e que, ao mesmo tempo, mais leva dúvidas a qualquer tipo de programador, estamos falando da Inteligência Artificial (IA).
Introdução à Inteligência Artificial
Não é de hoje que o termo Inteligência Artificial está sendo discutido, aliás desde o fim da segunda guerra mundial esse termo vem sendo utilizado, porém com as dificuldades tecnológicas da época, não foi possível desenvolver de forma prática as ideias inicialmente teorizadas.
Diferença de termos
Para iniciar o estudo nesta área é necessário o entendimento da diferença de alguns termos. Normalmente, quando é feita uma pesquisa sobre o tema, aparecem diversos outros termos, como Machine Learning, Deep Learning, Data Science e a própria Inteligência Artificial. O Machine Learning e o Deep Learning pode-se dizer que são subáreas da IA e ambos estão relacionados ao aprendizado. O Machine Learning é o famoso aprendizado de máquina e o Deep Learning, por sua vez, pode ser definido como o aprendizado profundo. A diferença entre eles é basicamente que o Deep Learning é uma sofisticção do Machine Learning, tanto em requisitos tecnológicos quanto na quantidade de dados necessários. Então podemos organizar Inteligência Artificial, Machine Learning e Deep Learning como no diagrama abaixo:
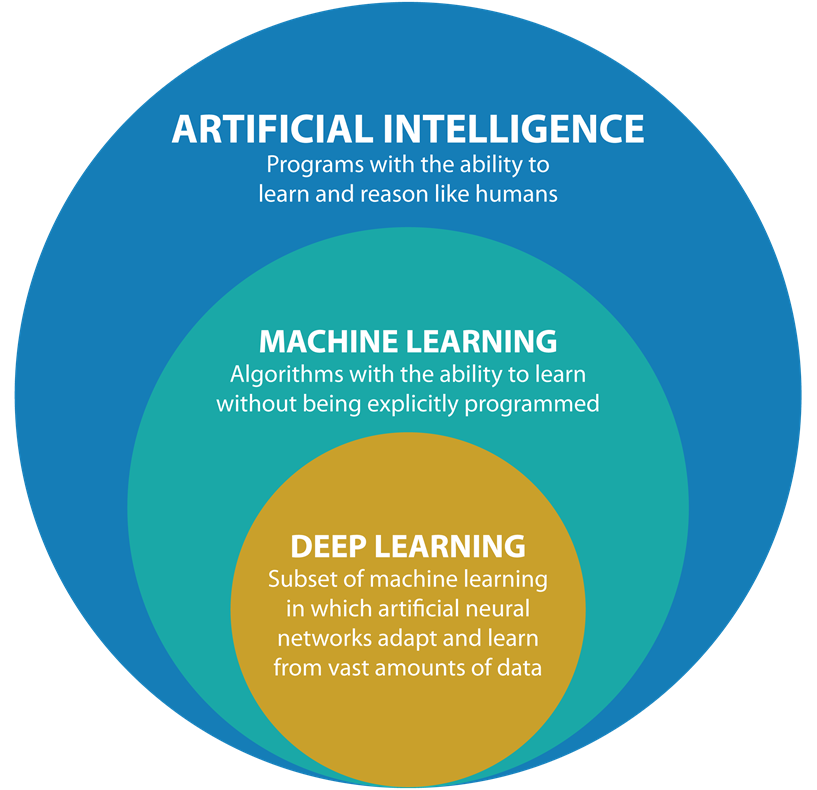
Já o Data Science pode ser colocado como outra área, a parte da Inteligência Artificial, mas que, ao mesmo tempo, é complementar e fundamental. Data Science está relacionado ao tratamento dos dados que serão futuramente utilizados por Inteligência Artificial, que pode ser tanto Machine Learning como Deep Learning.
Por onde começar?
Uma das maiores dúvidas de quem pesquisa sobre o assunto é: Por onde começar? Qual linguagem devo aprender? Devo fazer algum curso? Essas perguntas são muito comuns já que a Inteligência Artificial, por mais que não seja uma área nova como já vimos, começou a ser realmente popular e viável há apenas alguns anos. Com uma pesquisa breve, a linguagem que mais aparecerá conteúdo com certeza será a linguagem Python e talvez algo sobre a linguagem R, porém esta última é mais utilizada para o estudo de Data Science e a estatística por trás dos dados que são utilizados, mais tarde, pela Inteligência Artificial. A não ser que você domine outra linguagem que tenha aplicação dentro da área de IA, o Python realmente é a melhor opção já que possui uma curva de aprendizagem relativamente baixa, tem uma sintaxe muito simples, ao mesmo tempo, que muito poderosa e com tecnologias e bibliotecas, que veremos mais tarde, especificamente aplicáveis à IA.
Aplicações
Como existem muitas aplicações dentro da IA, e muitas delas nós nem percebemos quando estamos utilizando, é complicado saber por onde começar e o que desenvolver primeiro. Os chatbots ou os próprios bots são um dos mais “visíveis” para o público em geral, porém a maioria já possui uma pré-programação, além de que possivelmente, caso seja aplicado uma IA nesse bot, torne um problema muito complexo para um primeiro momento. Outra tecnologia que é considerada mais complexa e muitas pessoas não associam à IA em si é a análise de imagens. A análise de imagens pode ser de diversos tipos, como análise de texto em imagens, reconhecimento facial, reconhecimento de objetos em geral, etc. Além disso, existem inúmeras outras aplicações, como sistemas de recomendação de conteúdo ou produtos, assistência pessoal e no próprio ensino, por mais que não seja amplamente utilizado por enquanto. Porém, para iniciar os estudos nesse mundo, a melhor forma e mais simples é utilizando dados e criando um sistema de predição comum, que consegue, a partir dos dados recebidos, aprender com eles e fazer classificações e previsões. A melhor forma de conseguir dados para usar como exemplo é a partir da plataforma Kaggle. A plataforma Kaggle além de possuir diversas bases de dados, sobre os mais diversos assuntos, também possui desafios para quem quer aplicar os conhecimentos de IA e Machine Learning e, ao mesmo tempo, competir e concorrer a prêmios dependendo do desempenho do participante.
Desenvolvimento
Entrando na parte prática, desenvolvemos uma aplicação de Machine Learning simples, utilizando uma base de dados com registro de salários em relação a anos de experiência, então o que iremos fazer é criar uma aplicação que tenta prever o salário de alguém baseado nos anos de experiência. Antes de iniciar o desenvolvimento, é preciso fazer algumas instalações e configurar o ambiente. Primeiramente, será necessário a instalação do Pycharm, que será a IDE utilizada, e o Python, neste link para o Windows e para Linux deve ser executado os seguintes comandos:

Este comando irá instalar tanto o Python quanto o PIP que é o Gerenciador de Pacotes nativo do Python, que serve para instalar dependências/bibliotecas dentro do seu projeto.
Para utilizar os Data sets (conjuntos de dados) da plataforma Kaggle é necessário criar uma conta dentro da plataforma. Após isso, acesse o Data set Salary a partir deste link e faça download do arquivo Salary.csv. Basicamente, um arquivo csv armazena informações separadas por vírgula e é muito utilizado em Data sets para Machine Learning. O arquivo Salary.csv possui informações do salário e dos anos de experiência de 35 empregados.
Abrindo o Pycharm, deve-se ver algo parecido com a imagem abaixo. Agora, clique no botão New Project e nomeie seu projeto e escolha onde ele será salvo.
Após a criação do projeto, poderá ser visto um código padrão em um arquivo chamado main.py, porém este código pode ser totalmente apagado, pois usaremos este arquivo para colocar nosso código.
O primeiro passo a ser feito é instalar algumas dependências/bibliotecas que serão usadas tanto para o Machine Learning quanto para a visualização dos resultados. No canto inferior esquerdo do Pycharm, clique em Terminal e execute os seguintes comandos (para Linux e Windows):

De forma simplificada, Pandas é uma biblioteca Python criada para análise e manipulação de dados, por exemplo, mexer com arquivos csv. Já o sklearn ou scikit-learn é uma biblioteca desenvolvida especificamente para aplicar Machine Learning, possuindo diversas ferramentas/funções para auxiliar e facilitar a implementação. Por fim, a matplotlib é uma biblioteca que permite uma apresentação melhor dos dados a partir da criação de gráficos, já que muitas vezes é complicado entender os resultados apenas pelos números.
Antes de iniciar o código é importante que o arquivo Salary.csv, que foi instalado anteriormente, seja movido para a pasta do projeto. O caminho do projeto pode ser visto ao lado do nome do projeto, copie ou recorte o arquivo e coloque dentro da pasta principal do projeto, como na imagem abaixo:
O primeiro passo no desenvolvimento é importar as bibliotecas, que foram instaladas, para serem usadas dentro do código. A importação das dependências pode ser feita da seguinte maneira:

A cor do texto ficará dessa forma até elas serem utilizadas dentro do código. O primeiro import é da biblioteca inteira do pandas e podemos acessar as funções a partir da variável pd, que foi definida na imagem acima (pode ser qualquer outro nome). O segundo import é de uma das interfaces da biblioteca matplotlib, utilizada para casos mais simples, a pyplot, que poderá sempre acessada a partir da variável plt. O terceiro import é de uma classes dos modelos lineares do sklearn, o LinearRegression (Regressão Linear), que é uma das formas mais simples de previsão tanto na matemática quanto no Machine Learning. A partir dessa classe pode-se acessar alguns métodos/funções importantes para a aplicação. O último import é de uma função chamada train_test_split, que serve para dividir os dados do nosso arquivo csv em train (treino) e test (teste), dessa forma pode-se usar uma parte dos dados para treinar nossa aplicação de Machine Learning e a outra parte para fazer testes, impedindo que o nossa aplicação fique “viciada”, pois estaria testando sempre com os mesmos dados.
Para iniciar a implementação do código em si podemos começar lendo o arquivo Salary.csv e imprimir todos os dados lidos, como na figura abaixo:

Cria-se a variável data para armazenar os dados que vem do arquivo csv e para ler o arquivo utiliza-se a variável da biblioteca pandas, que foi definida nos imports acima, para acessar uma função chamada read_csv, que faz a leitura de um arquivo csv e retorna um DataFrame (quadro de dados), com o nome das colunas e as informações. Depois colocamos um print(data) para mostrar as 35 linhas provenientes da variável data, que contém todos os dados.
Clique Shift + F10 ou Shift + Fn + F10 para executar o código e visualizar os dados na parte inferior do Pycharm.
Como comentamos anteriormente, teremos que dividir os dados em train (treino) e test (teste), mas também é importante separar as colunas do salário e anos de experiência, para que possam ser analisados isoladamente. Para isso, escreva o seguinte código:

Cria-se a variável x para armazenar a coluna dos anos de experiência e a variável y para armazenar a coluna do salário, utilizando o método de seleção iloc, que seleciona dados a partir de números e retorna um array. Nesse caso, estamos selecionando todos os 35 dados de cada coluna. Após isso, cria-se 4 variáveis, um train e um test para cada coluna, para fazermos a separação a partir da função train_test_split(), que recebe como parâmetros: o x (array dos anos de experiência), o y (array do salário), o test_size (porcentagem dos dados que irão para teste) e o random_state (define se a divisão vai ser embaralhada toda vez que o programa for executado). No test_size passamos o valor 0.3, que significa que 30% dos dados serão de teste e o resto vai ser treino. Já no random_state passamos o valor 0 (ou qualquer outro número), isso significa que os valores de teste e treino sempre serão os mesmos, servindo para verificar se a aplicação está correta, porém podemos excluir esse parâmetro depois para deixar totalmente aleatório. Uma observação: as variáveis de train e test devem estar na ordem mostrada na imagem, pois o valor que elas recebem provém da função train_test_split(), que possui essa ordem por padrão.
Agora vamos começar a treinar a aplicação a partir dos dados de treino e criar a previsão a partir dos dados de teste, o que é extremamente simples utilizando o sklearn. Confira o código abaixo:

Cria-se uma variável model, referente a modelo, que será do tipo LinearRegression (classe), dessa forma podendo acessar todos os métodos desta classe. O fit é um método da classe LinearRegression, que recebe os dados de treino e “se adapta” a partir deles, ou seja, o nosso modelo vai tentar aprender com esse conjunto de informações, fazendo relações entre eles. Após isso, cria-se uma variável, chamada predictions, para armazenar as previsões que esse modelo fará a partir do que foi aprendido. Para isso, utiliza-se a função predict, que recebe o x_test (anos de experiência) e tenta prever qual salário cada um desses anos de experiência teriam, baseado nas análises feitas na função fit. Por último, utiliza-se o print para visualizar e comparar os valores que o algoritmo previu com os valores reais dos salários dos anos de experiência informados. Definindo o random_state como 0, os resultados devem ser esses:

Para uma melhor visualização dos resultados, o matplotlib possui algumas funções simples para criação de gráficos de regressão linear. Confira o código:

Utiliza-se da variável plt, declarada anteriormente nos imports, para acessar algumas funções básicas da biblioteca, como a scatter, que coloca pontos em um plano cartesiano a partir de uma posição x e y informada, além da definição da coloração dos pontos (nesse caso vermelho). Na função scatter, informa-se os dados corretos, de acordo com o arquivo Salary.csv, para comparar com as previsões feitas. A função plot cria uma reta baseada nos dados dos anos de experiência e nas previsões de salário realizadas pelo algoritmo. Por fim, utiliza-se a função show para mostrar o gráfico. Agora podemos executar o programa e, caso o random_state seja igual a 0, o resultado é esse:
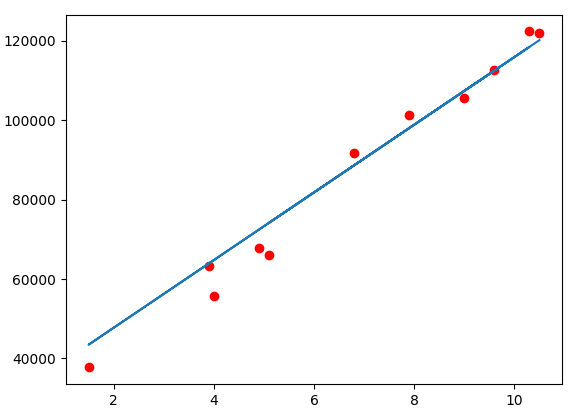
Com isso, podemos conhecer um pouco mais da área de Inteligência Artificial e suas diversas subáreas, assim como entender melhor como uma aplicação de Machine Learning funciona na prática. Caso tenha alguma dúvida ou queira um minicurso sobre o assunto futuramente, entre em contato com os petianos.
Referências