Olá pessoal, nesta edição do PET Redação vamos apresentar algumas técnicas de mineração de dados que têm auxiliado as organizações em seus processos de exploração em suas bases de dados, são facilitadoras na tomada de decisão, geram vantagem competitiva, e podem ser aplicadas em vários segmentos. Let’s bora!
“Mineração:
-
ação ou efeito de minerar; trabalho de extração do minério.
-
depuração do minério extraído das minas.”
Podemos usar como base o conceito de mineração encontrado no dicionário, pois seu objetivo com os dados, é encontrar os padrões e as informações que seriam consideradas como “pepitas” na extração e busca pelo ouro. Seu objetivo principal é utilizar dos conceitos de estatística e aprendizado de máquina (Machine learning, ML) para gerar resultados, predições e padrões relevantes, sendo que com consultas SQL apenas, seriam inviáveis. Vamos revisar alguns conceitos da área:
-
Inteligência Artificial: sistemas que aprendem, e seguem aprendendo conforme surgem novas possibilidades, onde dado um novo cenário, ele responde conforme as probabilidades de resultados para cada movimento.
-
Aprendizado de Máquina: os programas normalmente recebem dados de entrada, e após algum processamento são retornados os dados alterados na saída. ML utiliza da inteligência artifical, para receber dados, aprender com os mesmos e gerar programas na saída, programas que são criados com base nos padrões da base de dados.
Então, cabe à mineração de dados utilizar destes componentes para explorar grandes quantidades de dados e facilitar tarefas que seriam extremamente exaustivas para os humanos. Mas e como faz? Um dos processos mais importantes na mineração é o KDD (Knowledge Discovery in Databases), uma série de passos de normalização dos datasets para manipulação e visualização de resultados.
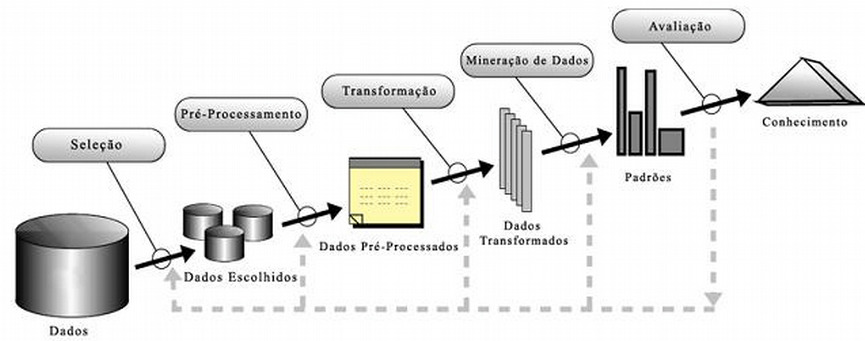 Figura 1: Processo de KDD, por Fayyad et. al.
Figura 1: Processo de KDD, por Fayyad et. al.Seleção: a primeira etapa consiste da seleção e formação do dataset, que pode incluir subconjuntos de dados de várias fontes, sendo algumas destas, API’s, planilhas, dados abertos, sistemas, data warehouses, etc.
Pré-Processamento: esta etapa visa verificar a qualidade dos dados. Muitas das bases normalmente vêm com dados faltantes ou inconsistentes, os quais devem ser ajustados de acordo com os princípios da consulta, para evitar os chamados ruídos. Por exemplo, em uma base que contém dados nulos, estes devem ser corrigidos ou removidos, dependo do objetivo da mineração.
Transformação: etapa de normalização, agregação, inserção de novos atributos, redução e sintetização dos dados. Os dados nesta etapa, são adaptados, dependendo do tipo de algoritmo que será rodado.
Mineração: aplicar técnicas e algoritmos dependendo de cada objetivo, como verificar hipóteses ou descobrir padrões de forma autônoma, que sejam úteis e desconhecidas aos analistas. Cabe nesta fase também, verificar quais algoritmos se comportaram melhor para aquela base de dados.
Avaliação: na última etapa, é feita a análise dos dados para que seja apresentado o conhecimento adquirido com aquelas informações e como irão impactar nos processos de decisão, com o propósito de deixar as informações mais simples de serem entendidas e apresentar sua relevância.
Estas etapas podem ser visualizadas como um fluxograma, onde os passos vistos na figura 1, podem ser ajustados dependo dos resultados. Nada impede, por exemplo, de retornar à etapa de pré-processamento depois de realizar a etapa de mineração, sendo que os dados não foram apresentados da maneira esperada.
Muito bem, mas e por onde eu posso começar?
Para aplicar a mineração, é fundamental definir bem os problemas que se pode resolver com cada base de dados. Este processo é bem simples, seguindo alguns passos, como a descrição do dataset, da classe, e os atributos da base que vamos utilizar para resolver o problema. Considere uma imobiliária que quer analisar o banco de dados de vendas de propriedades, e que deseja descobrir quais variáveis mais influenciam no preço da venda.
-
Descrição: Dados sobre o histórico de venda de propriedades de um imobiliária.
-
Classe: Quais variáveis mais influenciam no preço de venda das propriedades?
-
Atributos: área da propriedade, quantidade de quartos e preço da venda.
Após esta descrição é necessário definir em qual tipo de mineração tal problema se encaixa, sendo esta classificação fundamental para a escolha dos algoritmos. Esta análise requer de um estudo aprofundado nos 4 tipos, que são a Associação, Regressão, Classificação e Clusterização. Para mais informações, visite este site, que mostra um mapa para classificação de problemas e algoritmos.
Para o nosso problema vamos utilizar a regressão, pois utilizamos uma base histórica de vendas e queremos prever quais atributos mais impactam neste histórico de dados.
-
Descrição: Dados sobre o histórico de venda de propriedades de um imobiliária.
-
Classe: Quais variáveis mais influenciam no preço de venda das propriedades?
-
Atributos: área da propriedade, quantidade de quartos e preço da venda.
-
Classificação: Regressão.
Vamos aplicar agora um exemplo prático, na plataforma RStudio, que utiliza a linguagem R para mineração de dados. Primeiramente, vamos importar nossa base de dados usando a biblioteca DAAG, que contém base de dados prontas para exercícios, e carregar a base denominada houseprices:
library(DAAG) # biblioteca com bases prontas
data(houseprices) # carregando database
Vamos criar então, nosso modelo para machine learning, utilizando a biblioteca CARET de algoritmos:
set.seed(123) # "para controlar aleatoriedade"
library(caret)
# ------------ dividindo banco de dados para o modelo de Regressão -----------
dataindex <- createDataPartition(houseprices$sale.price, p= .7, list=FALSE)
# separação 70% do banco de dados para treino e o restante para teste.
housetreino <- houseprices[dataindex,]
houseteste <- houseprices[-dataindex,]
Nesta etapa, definimos que parte do banco será para treino e outra parte para teste, de modo que o modelo passe a treinar com os atributos para reconhecimento de padrões. Agora vamos utilizar os algoritmos no modelo:
# --- algoritmo GLM
modeloML1 <- train(sale.price~bedrooms+area, data = housetreino, method="glm")
# ---- algoritmo Random Forest
modeloML2 <- train(sale.price~bedrooms+area, data = housetreino, method="ranger", importance="impurity")
# comparando os algoritmos
listamodelos <- list(glm=modeloML1, ranger= modeloML2)
comparacao <- resamples(listamodelos)
dotplot(comparacao) #plotando análise de menor erro dos algoritmos
Para esta análise foram utilizados os algoritmos GLM e Random Forest, no qual o GLM se comportou melhor conforme a análise, apresentando menor erro.
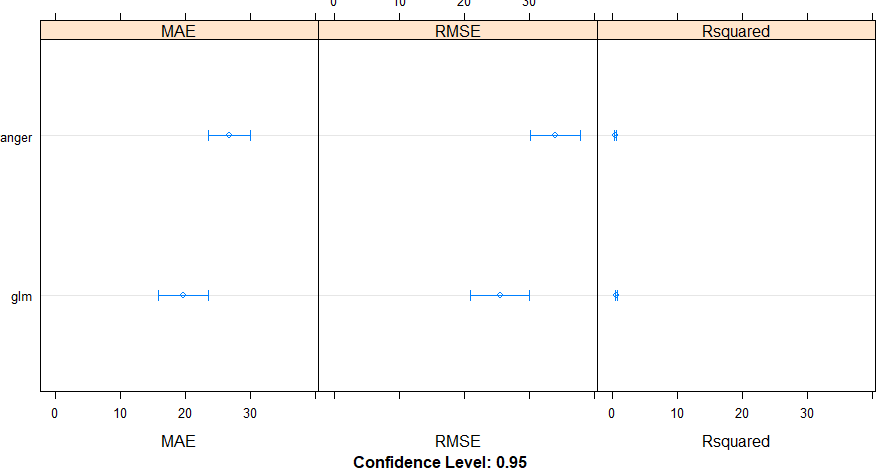 Figura 2. Comportamento dos algoritmos.
Figura 2. Comportamento dos algoritmos.
Para terminar, vamos usar a biblioteca caTools para analisar as variáveis mais importantes.
library(caTools)
plot(varImp(modeloML1)) # notamos a importância das variáveis em relação ao preço das propriedades
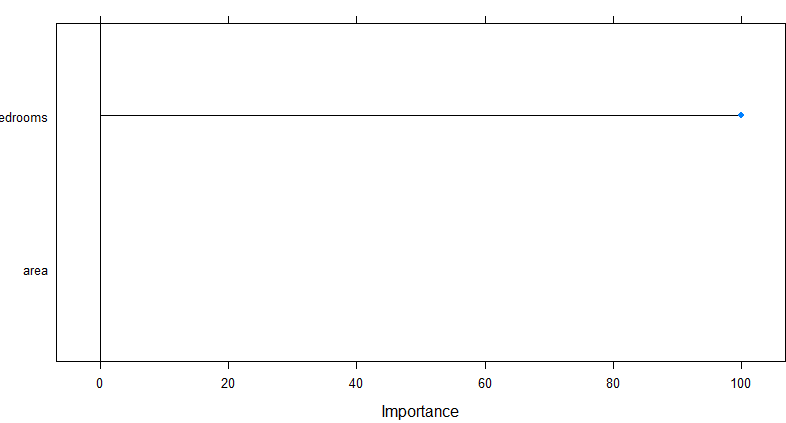 Figura 3. Importância das variáveis.
Figura 3. Importância das variáveis.Portanto, através da figura 3 deste exercício, notamos a importância do número de quartos, que influencia mais no preço de venda das propriedades do que necessariamente o tamanho da área.
Notamos, então, a importância da mineração de dados, que contém modelos e processos para auxiliar nas descobertas em datasets, que facilitam a tomada de decisão, geram vantagem competitiva, e que podem ser aplicados em vários segmentos. Além de plotar gráficos no excel, começamos a praticar a ciência de dados estruturada.